TRUST BOUNDARIES IN SECURITY ARCHITECTURE EXPLAINED
Where does trust boundaries really begin?
Trust boundaries do not begin with a security review.
They do not begin with a policy document, a compliance checklist, or a late-stage architecture assessment.
They begin much earlier.
They begin when a system starts interacting with itself and with the world around it.
A user opens a web application.
A frontend sends a request to an API.
An API calls another service.
A background job reads from a queue.
A workload requests access to a database.
A support process retrieves information from an administrative interface.
A third-party platform receives a payload through an integration.
That is where trust begins to form.
This is not because anyone sat in a room and formally declared what is trusted. It’s because the system starts behaving as though some things can be trusted and others need less scrutiny.
That is where architecture starts revealing its real character.
When I look at a system, I am not only looking at components. I am looking at interactions.
Who is speaking to what.
What is being requested.
What identity is being used.
What data is moving.
What assumptions are being made.
What happens if one side of the interaction is compromised, misconfigured, over-permissioned, or simply behaving in a way no one expected.
That is the point where trust boundaries start to matter.
Because a trust boundary is not just drawing lines on a diagram. It is understanding where trust changes, where verification must mean something, and where security controls need to hold because the interaction itself introduces risk.
This is one of the areas where systems quietly break when architecture is unclear.
A platform can look neat on a slide and still be carrying weak trust decisions inside its structure.
That is why trust boundaries are not a side topic in security architecture. They are one of the clearest indicators of whether a system has been designed with discipline or whether it has simply accumulated assumptions.
Why trust is often assumed too early
Most systems do not become weak because someone openly says let us trust too much.
It happens in a quieter way than that.
A service is internal, so it is treated as safe.
A backend component sits inside the same cloud environment, so it is treated as lower risk.
An API is called by another known service, so validation becomes lighter over time.
A workload already has access to a data store, so no one revisits whether that level of access is still justified.
An admin path is broad during delivery and remains broad because reducing it later feels inconvenient.
These decisions often sound reasonable in the moment. That is exactly why they persist.
Each one looks small enough to tolerate. Each one sounds operationally helpful. Each one appears to support delivery.
But systems are not shaped by single decisions in isolation. They are shaped by what those decisions add up to over time.
This is where trust starts spreading in ways no one explicitly planned.
An internal API becomes broadly trusted because it has never caused visible trouble.
A shared service becomes a gateway to multiple sensitive paths.
A lower-risk workload gains access that was originally meant only for a narrow use case.
One privileged component becomes the bridge between several parts of the platform.
Nothing may look dramatic.
The application still works.
The platform still scales.
The delivery team still ships features.
But structurally, the system is already changing.
Trust becomes wider.
Containment becomes weaker.
Access becomes harder to reason about.
Control placement becomes more difficult.
Visibility becomes more fragmented.
This is one of the reasons trust boundaries deserve more attention than they usually get.
Many people define them.
Far fewer people explain how systems start to drift when those boundaries are vague, implicit, or poorly enforced.
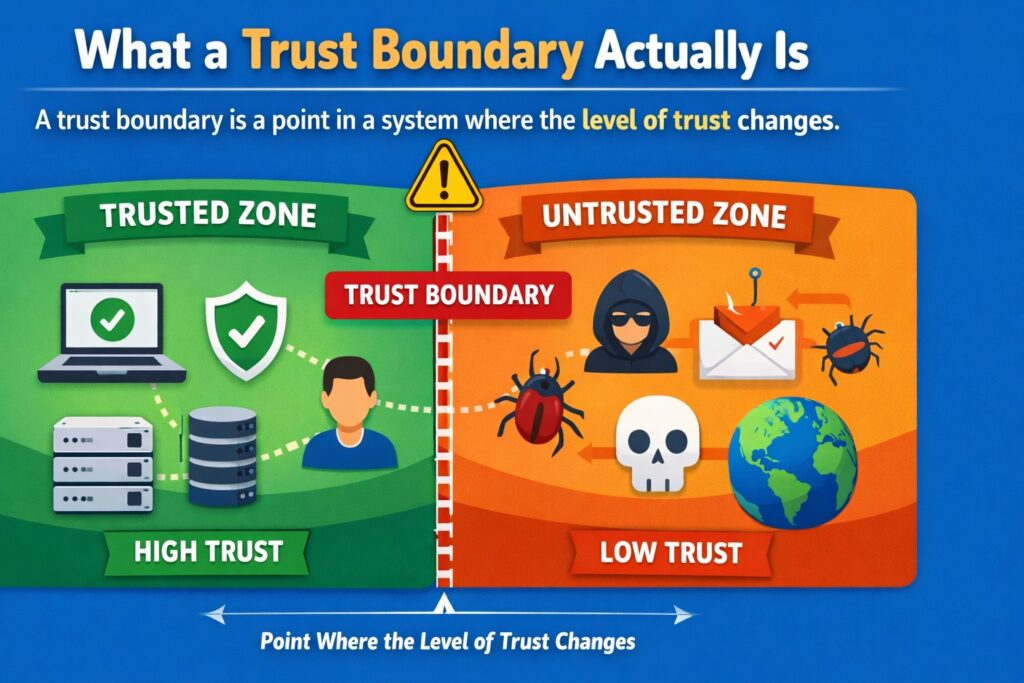
What a trust boundary actually is
A trust boundary is a point in a system where the level of trust changes.
That sounds simple, but it matters more than it first appears.
A trust boundary exists where one part of the system should not automatically trust another part without verification, constraint, or control.
That may be between:
- The public internet and your application
- A user and an API
- One service and another service
- A workload and a sensitive database
- An internal environment and an external provider
- An operational admin path and a production platform
- An AI component and the data or systems it can influence
At these points, something important is happening.
The system is deciding whether an interaction is acceptable.
It is deciding what proof to require.
It is deciding what access should be granted.
It is deciding what should be logged, restricted, validated, or denied.
That is why trust boundaries are so important in security architecture.
They show where security has to become real.
Without clear trust boundaries, systems begin to behave as though trust is inherited automatically.
With clear trust boundaries, systems can enforce trust deliberately.
That difference affects almost everything else:
- Access decisions
- Segmentation
- Identity enforcement
- Validation
- Secrets handling
- Logging
- Monitoring
- Incident containment
- Governance review
A trust boundary is not a theory point. It is an operating condition of the platform.
If the boundary is clear, security can act with precision.
If the boundary is unclear, security becomes vague, scattered, and reactive.
Internet to application: the boundary people notice first
The boundary most people recognise immediately is the one between the public internet and the application.
That makes sense. It is visible. It feels obvious. It is where untrusted external requests enter the system.
At this point, the architecture should already be thinking clearly.
Who is making the request.
How identity is established.
How input is validated.
How sessions are managed.
How malformed or hostile requests are handled.
What the application exposes.
What should happen before access is granted.
This boundary matters because it is the point where external activity meets internal processing.
It is where the system decides whether it understands the interaction well enough to allow it any further.
This is where controls such as authentication, rate limiting, request validation, API gateway logic, bot protection, web application protections, and session controls often sit.
But even here, the point is not simply to list controls.
The point is to understand why this boundary matters architecturally.
The internet is not your environment.
Requests originating there do not inherit trust.
Input crossing this boundary must be treated with care.
Identity must be established, not assumed.
If this boundary is weak, the rest of the platform can be exposed quickly.
But this is also where teams can become overconfident.
They secure the external edge and feel reassured. They believe that once traffic has passed through the frontend or gateway, it is now safely inside the trusted zone.
That is where many architectures begin to weaken.
Because the internet-to-application boundary is only the first trust boundary. It is not the only one, and in many modern systems it is not even the one that causes the most structural weakness over time.
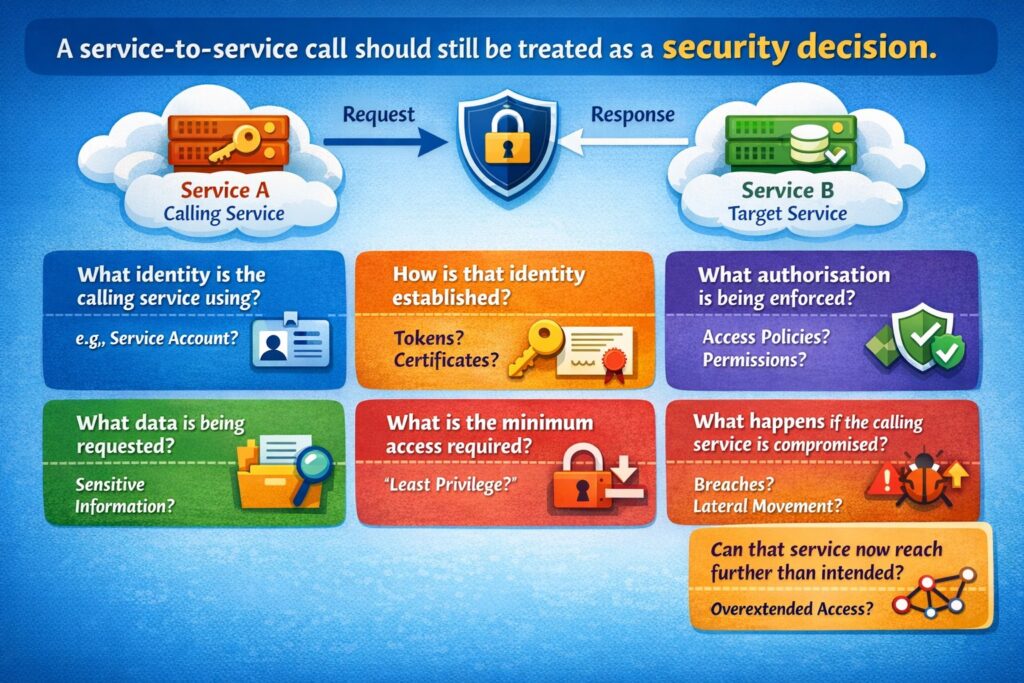
Service to service: where systems quietly weaken
This is where trust problems often become harder to see.
One internal service calls another service.
On paper, it looks straightforward.
It is inside the platform.
It is behind the edge layer.
It is part of the same product or programme.
It may even sit inside the same cloud account, subscription, cluster, or network segment.
So trust starts getting inherited.
That is where systems quietly weaken.
A service-to-service call should still be treated as a security decision.
What identity is the calling service using?
How is that identity established?
What authorisation is being enforced?
What data is being requested?
What is the minimum access required?
What happens if the calling service is compromised?
Can that service now reach further than intended?
These are not optional questions. They are central architecture questions.
Because internal services are not automatically safe simply because they are internal.
If a service is compromised and there is no meaningful trust boundary between it and downstream services, compromise can spread quietly.
A weak internal trust model usually looks ordinary at first.
A backend API accepts calls because the caller comes from inside the environment.
An internal token is trusted too broadly.
One service can query another with more scope than its function justifies.
Shared credentials remain in place because narrowing access would take time.
Mutual authentication is inconsistent across different service paths.
Nothing may look broken in normal operation.
That is what makes this dangerous.
The weakness only becomes fully visible when something goes wrong.
Then teams discover that one compromised service can:
- Call multiple downstream services
- Retrieve more data than expected
- Perform actions beyond its intended function
- Pivot into administrative or operational paths
- Bypass the neat assumptions in the architecture deck
This is why service-to-service boundaries matter so much in modern environments.
APIs, microservices, serverless workflows, containerised platforms, event-driven processing, and SaaS integrations all create dense interaction patterns.
The more interactions a system has, the more trust boundaries it contains.
If those boundaries are not explicit, internal trust starts behaving like implicit trust.
That is where containment begins to disappear.
Workload to data: where exposure becomes real
One of the most important trust boundaries in any system is the boundary between a workload and data.
A workload might be a container, a virtual machine, a serverless function, a background worker, an application process, or another runtime component.
At some point, that workload wants access to a data store.
A database.
An object store.
A queue.
A search index.
A file system.
A secrets store.
This is where exposure becomes real.
A workload does not just connect technically. It crosses a trust boundary.
At that point, architecture has to answer some serious questions.
Does this workload need to read this data at all?
Does it need full records or only part of the dataset?
Should it be allowed to write, update, delete, or only read?
Does it require persistent access or task-specific access?
What identity is used to access the store?
Is access scoped tightly enough to function?
Can the workload reach other datasets it should never see?
This is where many systems quietly overexpose themselves.
A workload is granted broad database permissions because fine-grained access was not designed early enough.
A service account ends up with table-wide or store-wide privileges.
Sensitive records become reachable by components that only needed summary data.
Operational tools gain direct data access because it felt easier than designing a proper support path.
The system may still behave normally from the user’s perspective.
But the architecture is already carrying structural weakness.
If that workload is compromised, the question is no longer just whether an attacker gained execution in one component.
The question becomes what data can now be reached, copied, changed, or exfiltrated.
That is why workload-to-data trust boundaries deserve careful design.
This is not just encryption or database hardening.
It is whether the structure of access reflects real need.
If it does not, then data exposure risk spreads quietly through normal system behaviour.
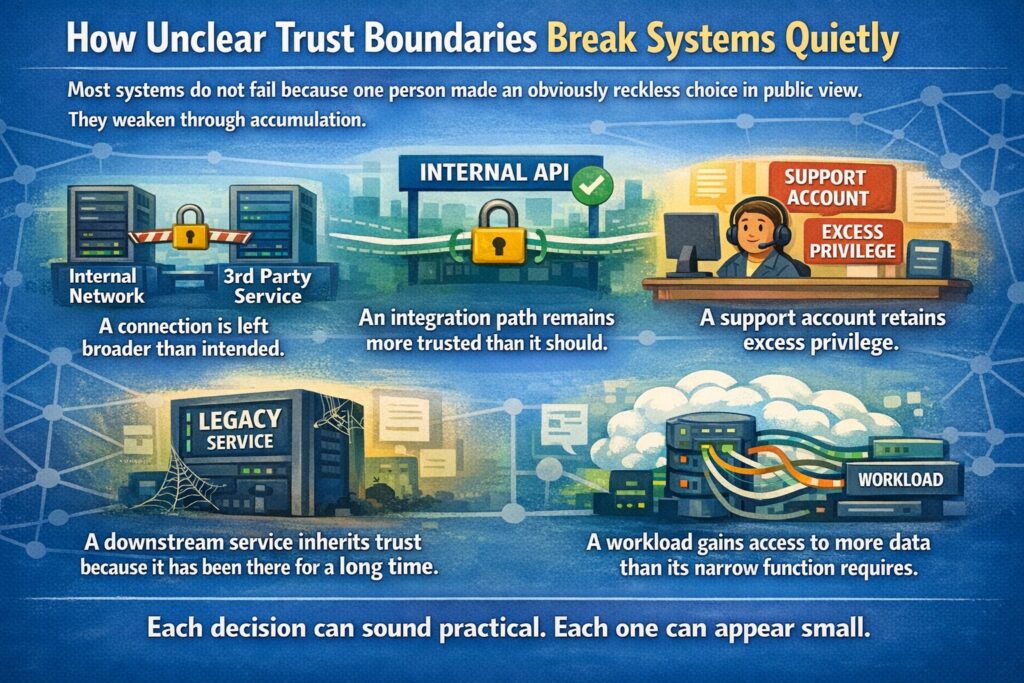
How unclear trust boundaries break systems quietly
Most systems do not fail because one person made an obviously reckless choice in public view.
They weaken through accumulation.
A connection is left broader than intended.
An integration path remains more trusted than it should.
A support account retains excess privilege.
A downstream service inherits trust because it has been there for a long time.
A workload gains access to more data than its narrow function requires.
Each decision can sound practical. Each one can appear small.
But unclear trust boundaries produce a particular kind of weakness.
They remove friction where friction was necessary.
Good architecture does not add random difficulty. But it does place meaningful checks where trust changes.
When that discipline is missing, systems start behaving as though everything inside the platform is trustworthy by default.
That is how small problems become larger incidents.
A token intended for one service is accepted too widely.
A compromised internal component can query several downstream services.
A lower-risk application tier reaches sensitive data stores directly.
An internal API becomes a path into functions no one expected to expose that way.
This is what I mean when I say systems quietly break when boundaries are unclear.
They do not always collapse.
They do not always announce the problem dramatically.
They simply become easier to move through, harder to contain, and more difficult to govern.
Then later, during assurance, incident response, or architecture review, teams start hearing familiar sentences.
We did not realise that service could reach that.
We thought that token was scoped more tightly.
We assumed the internal path was already protected.
We did not expect support tooling to expose that much.
We will need to fix this in a later phase.
That is not usually a tooling problem first. It is an architecture problem.
Trust boundaries and access decisions
Access decisions only make sense when trust boundaries are clear.
If the boundary is vague, access tends to become broad because no one can confidently define where trust should stop.
Once a trust boundary is explicit, the architecture can make better decisions.
Who is this caller?
What identity should be accepted here?
What should this identity be allowed to do?
What should it never be able to do?
How long should the access last?
What evidence should exist that the access was used properly?
This is where least privilege stops being a slogan and becomes a design practice.
Because least privilege is not something you sprinkle onto a live platform after years of accumulated assumptions.
It depends on knowing where trust changes and what that change should mean.
For example:
At the internet-to-application boundary, the system may allow anonymous browsing for public content but require strong authentication for account management.
At the service-to-service boundary, one backend service may be permitted to invoke a narrow API operation but not retrieve whole datasets.
At the workload-to-data boundary, a reporting function may only need read access to aggregated data, not full write access to production records.
Without trust boundaries, those distinctions blur.
Then access becomes difficult to justify, difficult to review, and difficult to reduce.
This is also where identity matters so much.
Users are not the only identities in a platform.
Services have identities.
Workloads have identities.
Automation has identities.
Administrators have identities.
Integrations have identities.
Every meaningful interaction should connect back to something known, scoped, and governable.
That is what turns access into something architecture can defend.

Trust boundaries and control placement
A lot of security discussions focus on whether a control exists.
That is only part of the story.
The more important question is whether the control sits in the right place.
Trust boundaries help answer that.
A control should be placed where trust changes in a way that matters.
At the point where a user enters the application.
At the point where one service calls another.
At the point where a workload requests data.
At the point where an admin process performs a privileged action.
At the point where data leaves the platform for a third party.
This is what good control placement looks like.
Not random layers of defensive tooling scattered across the platform, but controls aligned to the architecture of trust.
This matters because badly placed controls create false comfort.
Strong edge authentication does not solve uncontrolled internal trust.
Encryption at rest does not solve excessive application-level exposure.
Monitoring does not solve trust decisions if it is observing the wrong events.
A secrets vault does not solve over-permissioned workloads if the identity model is weak.
Controls only shape behaviour when they are placed where important system decisions are being made.
That is one of the clearest reasons trust boundaries matter in cybersecurity architecture.
They help determine where controls need to sit so they can actually influence risk.
This is also where proportionality matters.
The Blueprint Method™ approaches this with a simple discipline: controls should reduce identifiable risk without creating unnecessary complexity.
Over-engineering wastes capacity.
Under-engineering invites compromise.
Precision creates resilience.
That principle only works when trust boundaries are understood properly.
Trust boundaries and visibility
A system that cannot see across its trust boundaries cannot govern itself properly.
Visibility is not just producing logs. It is making boundary-crossing activity understandable.
You need to know:
- Who crossed the boundary
- What identity was used
- What was requested
- What was allowed or denied
- What data was involved
- What changed as a result
- Whether the activity matched expected behaviour
If you cannot answer those questions, then you are operating with blind spots exactly where they matter most.
This becomes critical during:
- Incident response
- Assurance reviews
- Governance boards
- Forensic investigation
- Operational troubleshooting
- Access reviews
Poor observability usually follows the same pattern as poor trust design.
Teams log a lot of events, but not the right ones.
They collect activity, but not enough context.
They can see traffic, but cannot reconstruct meaning.
They know something crossed a system boundary, but not whether it should have.
Good visibility should follow trust boundaries.
Identity events should be visible.
Authentication outcomes should be visible.
Authorisation decisions should be visible.
Privileged operations should be visible.
Sensitive data access should be visible.
Cross-service calls that matter should be traceable.
This is one reason security architecture has to think beyond simple control presence.
A control that cannot be observed properly becomes harder to trust operationally.
A platform that cannot show what happens when trust changes becomes harder to govern.
That is why trust boundaries connect directly to visibility.
The boundary is not only where a decision is enforced. It is where the decision needs to be observable.
Trust boundaries in cloud and distributed environments
Modern digital platforms are complex systems.
Cloud infrastructure, APIs, SaaS platforms, distributed applications, and AI components all interact across multiple environments.
Data moves constantly.
Identity travels across services.
Decisions are made by both humans and automated systems.
This is exactly why trust boundaries matter even more now.
A modern platform may include:
- Internet-facing applications
- Multiple APIs
- Internal microservices
- Containers and orchestration platforms
- Serverless functions
- Managed databases
- Queues and event streams
- SaaS integrations
- Administrative portals
- CI/CD pipelines
- Monitoring and response tooling
- AI-enabled components
This is not just a technology stack. It is a trust structure.
Every one of those interactions introduces questions about:
- Identity
- Access
- Validation
- Segmentation
- Data movement
- Observability
- Containment
When trust boundaries are vague in these environments, risk spreads quickly.
One service trusts another too broadly.
One workload can reach too many datasets.
One automation path crosses several environments without enough constraint.
One integration account can do far more than the business purpose requires.
Cloud and distributed environments make this more visible because the number of interactions grows rapidly.
They also make it easier for teams to assume that platform features alone will solve the problem.
They help, but they do not replace architecture.
Zero trust architecture design is not achieved by buying products. It is achieved by structuring trust properly across the system.
That means being clear about where trust changes, how identities are verified, how access is scoped, and how movement across boundaries is constrained and observed.
The same applies to AI-enabled systems.
AI introduces new trust boundaries too.
Between users and prompts.
Between prompts and models.
Between models and retrieved context.
Between AI outputs and downstream actions.
Between automated decision support and human oversight.
Implicit trust in model behaviour is not acceptable.
AI components must be governed with the same structural clarity as traditional platforms.
How security architects work with trust boundaries in practice
A good security architect does not wait for a late review to start thinking about trust boundaries.
This work starts early, while the system is still being shaped.
The questions are practical.
Where are the real entry points?
Which interactions carry more risk than they first appear?
What is currently being trusted without enough basis?
Where does identity need to be explicit?
Where should access stop?
Which paths create the greatest risk of lateral movement?
Where should visibility be strongest?
What happens if this component is compromised?
What does it open up next?
This is not abstract work.
It sits close to platform design, engineering, operations, and governance.
In real projects, trust boundary analysis often reveals weaknesses that would otherwise stay hidden inside normal delivery decisions.
A service has direct data access it does not really need.
A support workflow reaches across environments too broadly.
An API contract assumes upstream validation that was never formalised.
A platform component is treated as trusted simply because it sits behind the perimeter.
This is where security architecture adds real value.
It’s not by slowing things down for the sake of it, but by making structural risk visible before it becomes normal.
Once a team sees trust boundaries clearly, several things become easier to design well:
- Identity models
- Access patterns
- Control placement
- Segmentation decisions
- Data minimisation
- Monitoring strategy
- Governance rationale
That is the practical discipline.
You are shaping the conditions that allow the system to remain secure, observable, and governable under real operational pressure.
The five-layer thinking behind stronger trust design
One practical way to keep trust boundary analysis grounded is to examine the platform across five layers:
- Business
- Data
- Application
- Technology
- Operations
This is not just a presentation model. It is a way of making sure trust is not treated too narrowly.
Business layer
What is the system here to do?
What would matter if it failed?
Who depends on it?
What type of harm would matter most?
Trust decisions should reflect business consequence.
A public information platform and a regulated case-management system should not carry the same trust assumptions.
Data layer
What data exists?
How sensitive is it?
Where does it move?
Where is exposure highest?
Which components truly need access?
Data trust determines the strength of controls.
Application layer
How does the application enforce trust?
How are users authenticated?
How are services authorised?
How is input validated?
How are privileged functions handled?
This is where trust becomes real behaviour.
Technology layer
How is the environment segmented?
How are workloads isolated?
How do components connect?
How are infrastructure boundaries defined?
What allows or restricts lateral movement?
Isolation determines containment strength.
Operations layer
Can activity be observed?
Can incidents be reconstructed?
Can changes be traced?
Can governance bodies review meaningful evidence?
Can recovery happen with enough clarity?
Secure systems must remain observable and governable.
A platform cannot be considered secure by design unless all five layers are addressed.
Security is structural, not cosmetic.
Where The Blueprint Method™ fits naturally
This is exactly where The Blueprint Method™ fits.
The Blueprint Method™ is a Secure-by-Design security architecture framework developed by Cyb-Uranus.
It provides a structured way to design platforms where security is embedded into the architecture from the beginning.
Instead of relying on tools or compliance checklists, the method focuses on how systems are structured.
It defines:
- Explicit trust boundaries
- Identity models
- Structured control placement
- Documented architectural decisions
- Governance-aligned security design
- Operational observability
The Blueprint Method™ enables organisations to design systems that are structurally secure, operationally sustainable, and defensible under governance and audit review.
This matters because many organisations still bring security into the conversation too late.
A system is designed.
A platform is built.
A programme moves into delivery.
Then security appears as a review. Controls are added after the architecture already exists.
That approach produces fragile systems. Security becomes reactive.
Cyb-Uranus approaches security differently.
Security is not added to systems. It is engineered into them.
The Blueprint Method™ analyses every platform across the five structural layers already described: Business, Data, Application, Technology, and Operations.
Its core principles are straightforward:
- Security must be engineered into system structure
- Trust boundaries must be explicitly defined
- Identity models must be deliberate and enforceable
- Security controls must be proportionate to risk
- Architectural decisions must be documented
- Governance must be embedded in delivery
- Systems must remain observable in operation
This architecture-first approach is one of the clearest ways to stop systems from quietly weakening through implicit trust.
How the Security Architect’s Blueprint turns this into a working system
Security architecture often fails for one simple reason.
It becomes documentation.
Large documents are written. Diagrams are produced. Controls are listed.
But when delivery pressure arrives, the architecture disappears and security becomes reactive.
The Security Architect’s Blueprint was created to solve this problem.
It provides a practical system for designing secure-by-design enterprise platforms that remain defensible, reviewable, and usable in real delivery environments.
It combines architecture thinking, secure-by-design governance, and assurance artefacts into a working framework.
The Blueprint gives security architects three integrated things.
1. The Blueprint Method™
A structured method for designing secure systems across the five layers:
- Business
- Data
- Application
- Technology
- Operations
This helps architects think clearly about trust, access, control placement, and operational security across the full structure of the platform.
2. Secure-by-Design Governance Framework
Architecture without governance creates undocumented risk.
The Security Architect’s Blueprint connects architecture decisions with:
- Threat modelling
- Architecture decision records
- Control baselines
- Assurance evidence
- Governance review
- Traceable risk rationale
- Explicit risk acceptance processes
This ensures that security decisions are explicit, traceable, reviewable, and defensible during audit and governance scrutiny.
3. The Blueprint Assurance Toolkit
The Blueprint also includes practical artefacts that help teams move from architecture thinking to delivery.
These include support for:
- Security architecture documentation
- Security non-functional requirements catalogues
- Secure-by-design control baselines
- Implementation checklists for engineering teams
- Cryptography and key management architecture
- Assurance and evidence tracking
This matters because modern systems are not only technically complex. They are also reviewed by governance boards, auditors, risk teams, architecture forums, and delivery leadership.
Security has to survive all of that.
The Security Architect’s Blueprint helps teams work through:
- Trust boundary definition
- Identity and access structure
- Control placement
- Architecture rationale
- Governance-ready documentation
- Implementation guidance for engineering
- Evidence and assurance thinking
That is the difference between security architecture as paperwork and security architecture as a working discipline.
Final thought
Trust boundaries are one of the clearest signs of whether a system has been architected with care.
They show where trust changes.
They show where verification must mean something.
They show where access should stop being assumed.
They show where controls need to be placed so they can actually affect behaviour.
They show where visibility needs to exist so activity can be governed properly.
When trust boundaries are unclear, systems do not always fail loudly.
They weaken quietly.
Access spreads.
Data moves further than intended.
Internal services inherit trust too easily.
Controls become harder to place properly.
Visibility loses context.
Containment starts to disappear.
That is why trust boundaries matter so much in cybersecurity architecture.
They are not just labels on a diagram.
They are part of the structure that determines whether a platform can remain secure, resilient, and governable over time.
The real work is not merely to define trust boundaries in theory.
It is to understand interactions, challenge assumed trust, identify where trust actually changes, and design the system so that access, controls, and visibility align to those points with precision.
That is how architecture becomes secure by design.
That is how systems stay governable as they grow.
And that is exactly where Cyb-Uranus, The Blueprint Method™, and the Security Architect’s Blueprint fit naturally.
They were built for this problem.
Not to add security after the fact, but to engineer it into the structure of the platform from the beginning.
Need help turning this into a working architecture?
Designing trust boundaries on paper is one thing. Getting them to hold in real cloud, API, distributed, and AI-enabled environments is another.
If you want secure-by-design architecture that is clear, implementable, governance-ready, and defensible under review:
Explore The Blueprint Method™
Get the Security Architect’s Blueprint
View Secure-by-Design Advisory Service
Request a conversation
Learn more about Cyb-Uranus
Understand How Secure Systems Are Actually Designed
Most security content focuses on tools.
This is about how systems are actually structured to handle trust, identity and risk.
I share practical insights on security architecture, secure system design and emerging threats.
